

A swarm of SLMs vs an LLM
Another chapter in the small vs mighty


Small things often move the biggest mountains. Ants build cities, raindrops carve canyons, tiny services power the apps we use all day.
Small language models fit that same pattern. They are fast, frugal, and easy to place close to users or data. In the right roles they punch far above their size, and ignoring them now would be like ignoring microservices when monoliths felt inevitable.
Large language models still shine at broad reasoning and open-ended synthesis, but a swarm of small models can collaborate, specialize, and route work with tight control over cost, latency, and privacy. This essay looks at how SLMs and LLMs complement each other, why a many-small approach changes what you can build, and how to design systems where the small parts add up to something surprisingly powerful.
The past year has been fascinating to watch. Everyone's been obsessing over the latest frontier models GPT-4, Claude, Gemini while quietly, a different conversation has been brewing in production environments. Teams are discovering that smaller language models aren't just budget alternatives; they're often the better choice.
I've been working with teams deploying both small and large models at scale, and the pattern is clear: the decision isn't about settling for less capability. It's about matching the right tool to the job. And increasingly, that tool is a small language model.
Let's talk about when, why, and how to make this choice.
Defining SLMs vs LLMs
The lines aren't as clear as you might think. It's not just about parameter count it's about deployment philosophy, operational constraints, and what you're trying to achieve.
Small Language Models (SLMs):
0.1B to 7B parameters
Run on edge devices, mobile, single GPUs
Sub-50ms latency typical
Examples: Phi-3 Mini, Llama 3.2, Gemma 2B
Large Language Models (LLMs):
13B+ parameters
Require cloud infrastructure, GPU clusters
100ms to 5s+ latency
Examples: GPT-4, Claude 3.5, Llama 70B
The interesting boundary is around 7B parameters. That's where deployment constraints kick in hard memory limits, quantization effectiveness, mobile viability. It's not arbitrary; it's where physics meets practicality.
The Easy Route: Just Use LLMs
Let's be honest starting with LLMs is the path of least resistance. Call OpenAI's API, get great results, ship fast. For most teams getting started, this makes perfect sense.
LLMs give you:
Broad capability: Handle almost any task reasonably well
Zero infrastructure: Someone else's problem
Rapid prototyping: From idea to demo in hours
Continuous improvement: Models get better without you doing anything
The math is simple: $0.01-0.10 per 1K tokens, no infrastructure headaches, predictable scaling. For many applications, this is the right choice and you should stop here.
But if you're processing millions of requests, need sub-100ms latency, have strict privacy requirements, or want to deploy to edge devices, the economics change quickly.
Why SLMs? The Compelling Scenarios
SLMs are not just cheaper LLMs. They invite different system designs. Benchmark scores alone hide how they reshape latency budgets, privacy posture, and total cost of ownership. The architectural shift is the story: place a capable small model close to the data and the user, and entire classes of experiences stop feeling laggy, leaky, or overpriced.
Latency-Critical Applications
Latency is the first unlock. Some interactions cannot wait half a second. Real-time voice agents feel human only when responses arrive inside a breath. Coding assistants preserve flow when completions appear faster than a keystroke pause. Simultaneous translation should track a speaker, not a transcript. Even humble edge workloads like sensor triage need decisions inside a control cycle. In these loops an SLM is not a compromise. It is often the only path to sub-50 ms without exotic caching.
Some applications simply can't wait 500ms for a response:
Real-time conversation: Voice assistants, gaming NPCs
Interactive coding: Code completion that doesn't break flow
Live translation: Simultaneous interpretation
IoT processing: Sensor data analysis at the edge
Privacy-First Deployments
Privacy is the next one. When data stays on a device or inside a facility, on-device SLMs keep the entire interaction local. A bedside clinical tool that parses notes, an internal finance screener that classifies transactions, a legal reviewer that summarizes privileged documents, a truly personal assistant that never calls home. Zero transmission by default. Fewer hard vendor dependencies because the boundary is physical rather than contractual.
When data can't leave the device or premises:
Healthcare: Patient records processing
Finance: Transaction analysis
Legal: Document review
Personal assistants: Truly private AI
Cost at Scale
Then comes cost at scale. The math is dull and decisive. If an SLM runs around 0.0001 to 0.001 dollars per 1K tokens and an LLM sits near 0.01 to 0.10, the gap is two to three orders of magnitude. At ten million tokens a month the spend is roughly 1 to 10 dollars for an SLM versus about 100 to 1000 dollars for an LLM. That delta buys observability, canaries, evals, and a thick layer of QA. At large volumes, economics become architecture.
The economics flip when you're processing high volumes:
SLM: $0.0001-0.001 per 1K tokens
LLM: $0.01-0.10 per 1K tokens
At 10M tokens/month, you're looking at $100-1K vs $100K-1M. The difference pays for a lot of infrastructure.
Edge Computing
Edge computing ties it together. Put the model where data is born and mobile apps work without a network, manufacturing lines run quality checks in real time, autonomous systems make split-second calls, and remote deployments keep operating through poor connectivity. This is not only about saving bandwidth. It reduces failure modes, removes round trips, and turns AI from a request into a capability.
Running AI where the data lives:
Mobile apps: No network dependency
Manufacturing: Real-time quality control
Autonomous systems: Split-second decisions
Remote locations: Limited connectivity
So how to choose?
Choosing between SLMs and LLMs comes down to four things. First, task complexity. SLMs excel at classification, routing, structured extraction, templated responses, and tightly scoped domain tasks, especially with light fine-tuning. LLMs win when multi-step reasoning, broad knowledge synthesis, open-ended creativity, or robust few-shot generalization across messy inputs is required.
Second, latency. Under 50 ms tends to be SLM territory. Between 100 ms and one second depends on other constraints. Beyond a second, LLMs are usually acceptable.
Third, privacy and compliance. On-device or on-prem SLMs provide zero data transmission by default, which simplifies regulatory conversations and builds trust while avoiding dependency on a single provider’s data path.
Fourth, the economic model. SLMs favor high-volume simple tasks, predictable costs, and long-term steady deployments. LLMs favor bursty or rare workloads, complex infrequent tasks, and situations where value per request dwarfs cost.
How-To: Building with SLMs
Building with SLMs benefits from a different playbook than working with large models. The goal is simple: pick the smallest model that clears the quality bar for the job, shape the memory and inference path so it stays fast and cheap, then add routing so bigger models are used only when there is real uncertainty or complexity.
1. Model Selection
For general tasks:
Phi-3 Mini (3.8B): Best balance of capability and efficiency
Llama 3.2 (3B): Strong performance, good ecosystem
Gemma 2B: Lightweight, good for mobile
For specific domains:
Code: CodeLlama 7B, StarCoder
Math/Reasoning: DeepSeek-Math, Llama specialized variants
Multilingual: mGLM, multilingual Llama variants
2. Optimization Techniques
Memory optimization:
Gradient checkpointing
Mixed precision training
Parameter-efficient fine-tuning (LoRA, AdaLoRA)
Inference optimization:
Dynamic batching
KV cache optimization
Speculative decoding
Smart Routing: The Best of Both Worlds
The most sophisticated systems don't choose between SLMs and LLMs they use both intelligently.
Cascade Routing
Start with SLM, escalate to LLM when needed:

A cascade pattern handles the majority case with an SLM and escalates only when needed. The request hits the SLM first, the system checks a confidence score line around 0.8, and if the bar is met the response returns in something like 45 milliseconds. If not, the same request moves to an LLM that may take closer to 800 milliseconds but delivers the depth required. Latency stays low for the common path and quality stays high for the hard cases.
Parallel Processing
Run both, take the first good result:
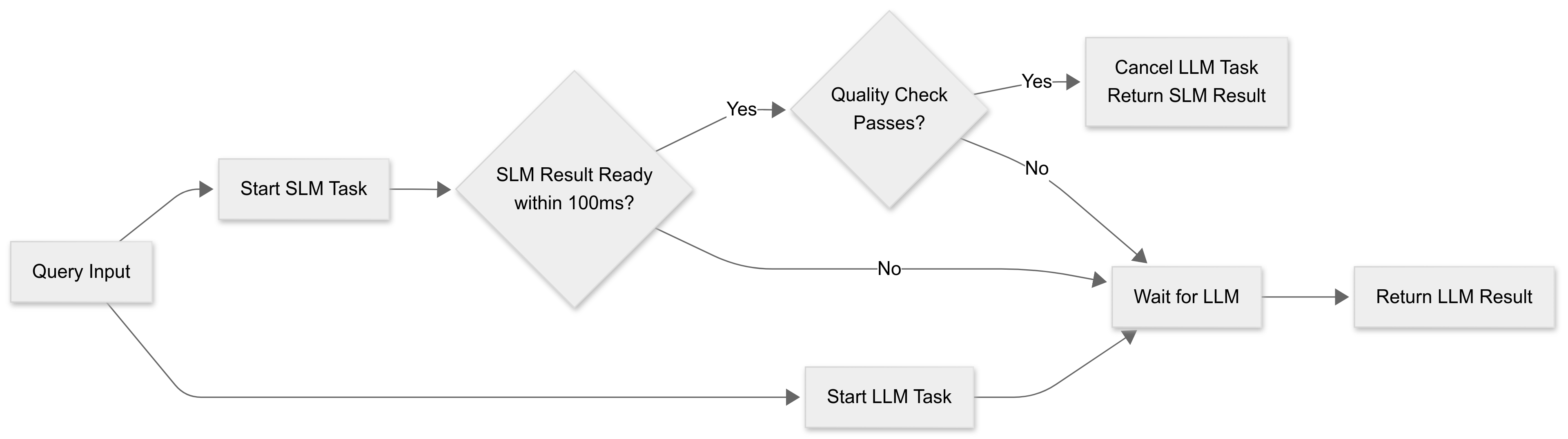
A racing pattern trades a little extra compute for predictability. An SLM and an LLM start in parallel. If the SLM produces a candidate inside 100 milliseconds, a quick quality gate evaluates it. Passing the gate cancels the LLM and returns the fast result. Failing the gate lets the LLM finish and return its answer. This keeps p95 and p99 latencies tight while preserving quality on the edge cases that truly need more capacity.
Context-Aware Routing
Route based on query characteristics:
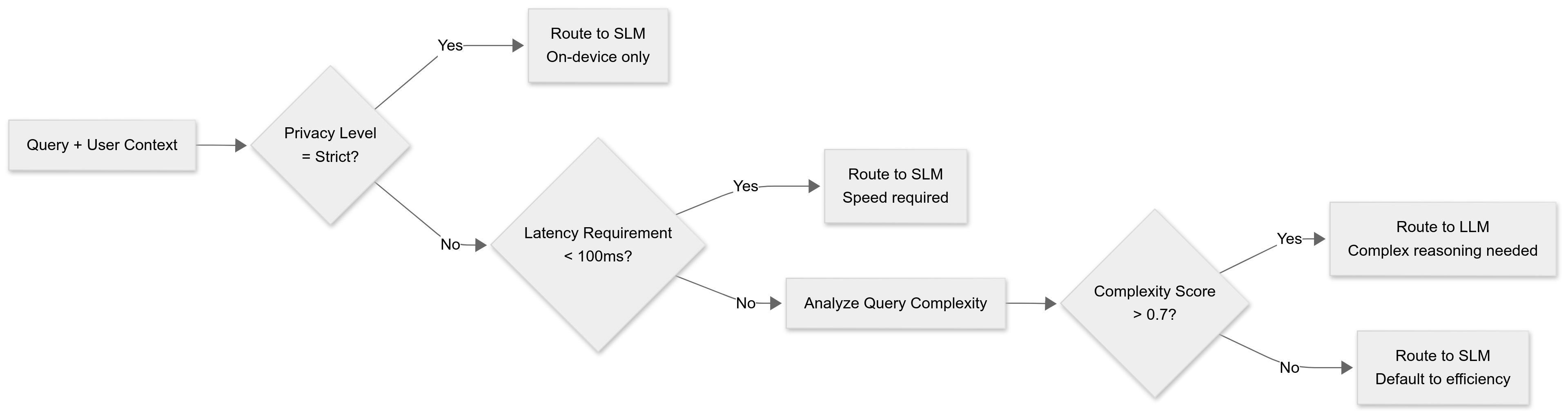
Context-aware routing lets the stack make smarter choices before any tokens flow. Privacy constraints route strictly to on-device SLMs. Tight latency budgets favor the small model for speed. Open privacy and relaxed latency push the decision to a complexity score derived from the query and recent outcomes. High complexity routes to an LLM for deeper reasoning, while everything else defaults to the SLM for efficiency.
Best SLMs Right Now
The landscape is moving fast, but here are the current standouts:
General Purpose
Phi-3 Mini (3.8B): Microsoft's efficiency champion
Llama 3.2 (3B): Meta's balanced approach
Gemma 2B: Google's lightweight option
Specialized Models
Code: CodeLlama 7B, StarCoder 3B
Math: DeepSeek-Math 7B
Multilingual: mGLM 6B
Conversational: Vicuna 7B, Alpaca variants
Emerging Contenders
Qwen 2.5: Strong reasoning capabilities
StableLM: Stability AI's latest
TinyLlama: Ultra-lightweight at 1.1B parameters
Realistically, most teams should start with LLMs and only move to SLMs when they hit specific constraints:
Latency: Can't wait 200ms+ for responses
Privacy: Data can't leave premises
Cost: Processing millions of requests monthly
Connectivity: Need offline capability
If none of these apply, stick with LLMs. The operational complexity of SLMs model selection, fine-tuning, deployment, monitoring isn't worth it unless you have a compelling reason.
But when you do have that reason, SLMs can be transformational. They enable applications that simply aren't possible with cloud-based LLMs: truly private AI, real-time interaction, offline operation, and cost-effective scale.
The future isn't SLMs vs LLMs it's intelligent orchestration of both. The teams building that capability now will have a significant advantage as AI becomes infrastructure.
What's your experience been with SLMs in production? Are you seeing the same patterns, or different constraints driving your decisions?
Thanks for reading,
Nikita Agarwal, AI Infra Weekly
Well articulated! Are smartphones really capable enough to store and run multiple SLMs specific to different use cases? I see that as a big bottleneck.....