

Artificially Intelligent Orchestration of Agents
Centralized policies. Decentralized agents. Deterministic outcomes.

Intelligence.
‘The ability to understand, learn and think’. My mind is plagued by the implications of ‘intelligence’ being available perpetually, autonomously: what changes? How should we build to cater to such change?
Last week, it was interesting to work out how simple, innocent-looking graphs could explode into 6 figure node beasts with even mid-scale production data. It was mind blowing to imagine intelligence being made available to each of those nodes, independently, reliably, at scale.
But is intelligence to be limited only to node-level functionality? Why should we limit ourselves to such boundaries?
Humans have probably been one of the most efficient species to have been able to organise and coordinate large groups of people into sub groups and orchestrate accomplishing a large goal. Some call it religion, others call it countries(jk!) That has been our mark of intelligence.
Now with Artificial Intelligence being made so much more mature, it is exciting to imagine AI coordinating large groups of AI units into subgroups to orchestrate accomplishing a large goal. At scale. Autonomously. Now that’s exciting.
Today, we talk about such intelligent orchestration.

Intelligent Orchestration
We have accomplished many a complex tasks with many sophistacated workflows, familarly called ‘DAGs’ They are almost the basis of any mature system, Kafka queues, Redis streams, all buzzing to keep your system guzzling. But here’s the interesting thing: with intelligence at our disposal, we now are free from the shackles of a ‘DAG’. We can now create sequences of actions to accomplish tasks at runtime - popularly called ‘agents’. However, only so much can be achieved by a single agent, we need ‘multi-agentic’ solutions going forward to accomplish complex tasks for us.
Agentic systems rarely follow a single, fixed path. Inputs vary, models disagree, and tools fail in surprising ways. Static DAGs force you to anticipate every branch in advance. Dynamic graphs invert that constraint. Edges are chosen at runtime by policies that read live state, which allows fanouts, model A or B trials, mid-run rewires, and graceful failure handling without redeploys.
Each step produces signals that should change where you go next: confidence scores, schema checks, cost budgets, latency SLOs, abuse filters. Hard-coding branches in code or YAML does not survive the real world where:
Quality or cost policies shift daily
Vendors or models need rapid A or B switches
Failures are non-uniform and require specific fallbacks
Partial progress must be reused to avoid recomputation
We can now treat routing as data that is evaluated at runtime against the current run state. Nodes are long-lived capabilities. Edges are conditional, late-bound, and modifiable while the run is in flight.
But how do you go about doing this, heck, should you even do this for your use case?
What scenarios would realistically even need such a ‘dynamic’ agent across defined agents?
Let us look at some concrete scenarios:
Highly variable inputs: You do not know which path is correct until you inspect the data.
Open-ended goals or exploratory tasks: You discover subgoals as you go.
Continuous optimisation: You want online A/Bs, bandits, or context-aware model selection without redeploys
Long-running or event-driven work: State evolves over hours or days.
Combinatorial explosion of possible flows: The number of potential edges is huge, for example: knowledge graph construction. As new entity or relation types are discovered, the manager dynamically fans out to relation-specific extractors, runs validators, and rewires the next steps based on confidence and coverage gaps.
When is this a bad idea?
Strictly regulated, safety-critical flows that require fully deterministic, auditable paths per version.
Very short, stable workflows where a static DAG is simpler to reason about and cheaper to operate.
Teams without strong observability or replay. Debugging emergent routing without traces, metrics, and replays is painful.
Now we have a new tool in our box, the power to recruit a team of agents and set up a ‘manager’ that would eternally assign tasks to these agents. What would building infra to achieve this usecase of AI look like?
The vanilla way of setting this up
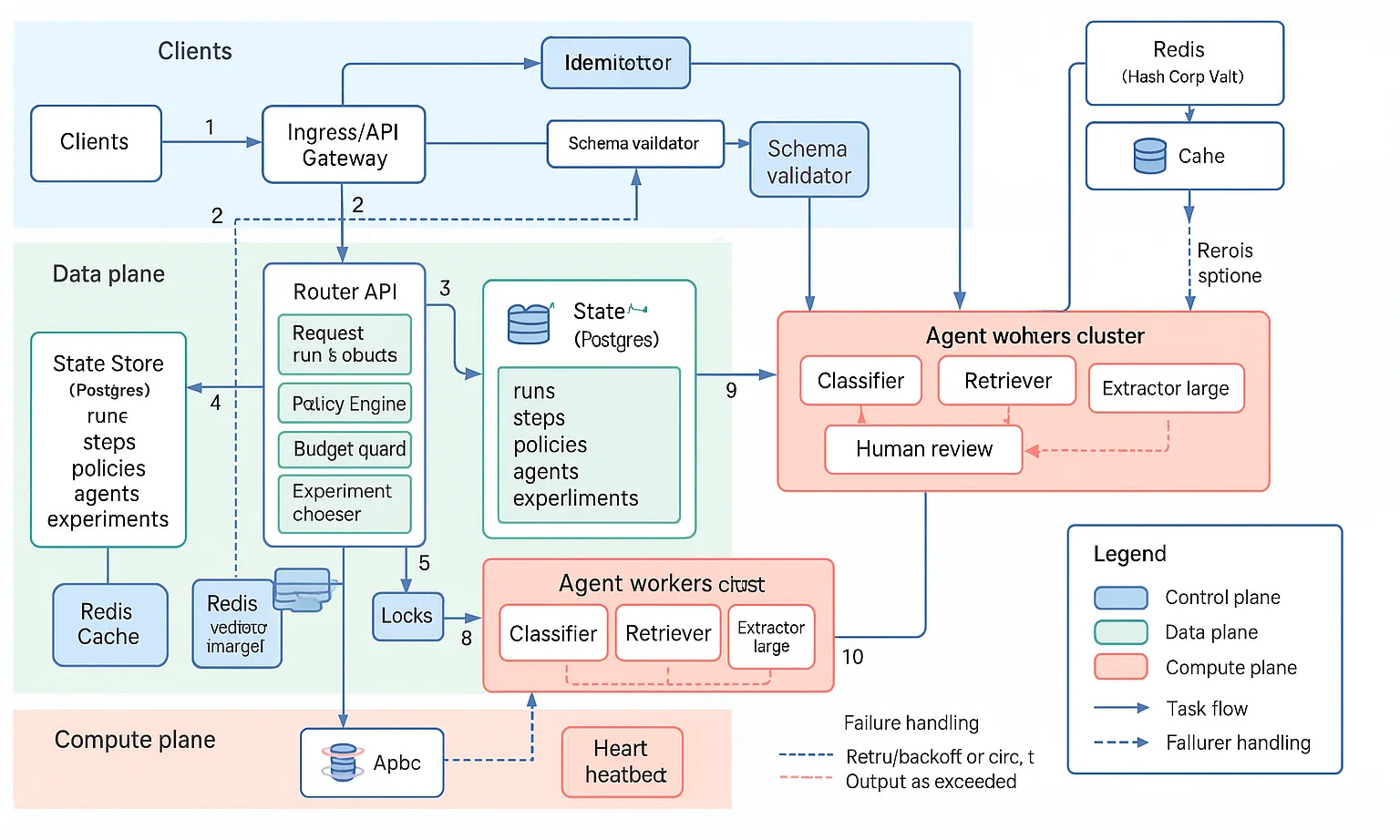
Router API owns run state and chooses the next hop. Keep the router small, stateless per request, and lock per run_id to avoid double routing.
Durable state in a database. Tables for runs, steps, agents, and policies. Store input or output as JSONB, plus metrics like cost and latency for policy checks.
Queues per capability. Use Redis Streams, Kafka, or RabbitMQ. Each agent worker consumes its queue, heartbeats, writes outputs, and emits step_done events.
Policy engine in data. Start with rule rows that match on features like confidence, elapsed time, tenant, budget remaining. Action is route-to, params, or fanout list.
Controls. Retries with backoff, budget guards, latency SLO guards, circuit breakers, and idempotency on step_id. Instrument with OpenTelemetry.
Tools to get you started
OpenAI Agents SDK and MCP
What you get: Agent runtimes with tool calling, MCP connectors for tools and data, server side execution primitives.
You implement: Central router and run level state, policy engine and budgets or SLOs, queues and worker processes, long run persistence and full observability.
Temporal
What you get: Durable workflows and activities with retries, timers, Signals or Updates, deterministic execution, task queues, visibility and versioning.
You implement: Data driven policy engine, agent registry and schemas, budget or SLO guards, experimentation, routing UI, plus the activity workers that call models or tools.
Exosphere
What you get: Central manager pattern for dynamic graphs, durable runs and steps, policy based routing, queues per capability, background agent execution, budgets or SLO gates, experiments, observability.
You implement: Define your concrete agents, schemas and guardrails, integrate specific tools or models.
Hatchet
What you get: Background task platform with spawning of child tasks, dynamic fanout, retries, concurrency limits, schedules.
You implement: Router level policy and state aggregation across tasks, budget or SLO gates, experiments or bandits, agent registry and guardrails.
Inngest
What you get: Event driven functions with fan out, waits, retries, scheduling, replay or DLQ managed for you.
You implement: Cross function run state, routing policies, budget or SLO enforcement, agent registry and worker code for AI calls.
AWS Step Functions
What you get: Choice and Map or Distributed Map for conditional or parallel routing, retries or catches, deep AWS service integrations, CloudWatch metrics.
You implement: Express runtime policies as Choice JSON or Lambdas, external agent workers, cost or latency budgeting, experiment control, richer tracing beyond CloudWatch.
Dagster
What you get: Dynamic ops or graphs, assets, sensors, type checks, IO managers, orchestration and scheduling.
You implement: Central router abstractions, runtime rewiring via API, budget or SLO gates, multi tenant policy tables, queue backed agent workers.
Prefect
What you get: Python flows with dynamic branching, retries, caching, deployments, result persistence, UI.
You implement: Cross flow router and policy in data, per capability queues, budgets or SLOs, experiments, registry of agents or tools.
Camunda 8 with DMN
What you get: BPMN orchestrations with Zeebe workers, DMN decision tables so routing rules live in data, message correlation, operations UI.
You implement: AI agent workers and schema validation, mapping model metrics to DMN inputs, budgeting logic, autoscaling by queue depth, observability integration for AI signals.
Ray Serve
What you get: Programmable request routers, dynamic backend selection, autoscaling, model composition, metrics.
You implement: Multi step run state and history, policy or experiment DB, budgets or SLOs across steps, tool integrations beyond model inference.
LangGraph
What you get: Node graphs with conditional edges, checkpoints, streaming, interrupt or resume, tool calling.
You implement: If avoiding explicit graphs you still need a central manager, plus policies in data, budgets, experiments, queue scaled workers and global run state.
Argo Workflows
What you get: Kubernetes native DAGs with loops, artifacts, retries, templates, parallelization, K8s autoscaling.
You implement: Externalized policy engine for runtime rewiring, agent registry and schemas, budgets or SLOs, cross run observability and replay.
With n independent components in a graph, possibilities of graph executions grow exponentially in order of n, to optimally know what should be done is a hard task, so is managing such variable execution.
There is no easy way today to get this going, and honestly the models are still maturing to handle such complex context and intelligently manage traffic realtime. I talk to founders each week building such solutions from ground up to support their use case, sharing the same story: a duct-taped framework which is ‘running’ and they are choosing to look the other way as capacity constrains.
I also think of the possibility that we might see models meant for such decision making. Or could we have AGI that could itself execute a task end to end without needing an external ‘manager’? Tools and mcps are unlocking such capabilities with higher order models as we go, what’s your bet?
-thanks for reading,
Nikita Ag