

Make your AI agent fail fast to succeed
Per node failure detection and resurrection is a necessity, not an option, here's the math worked out to simplify it for you

I am betting on the increasing autonomy of computer systems going forward, driven by rapid advances in artificial intelligence. This implies that many interacting agents and solutions will collaboratively work towards common goals, potentially running for extended periods, hours or even days in the background.
While we haven't fully reached this stage yet, we are currently experiencing its precursor: long-running AI workflows. These workflows are well-defined processes with fixed inputs, sequential steps, and expected outputs. They're widely used in various applications today, such as:
Database queries
Deep research across multiple domains
Coding agents and assistants
As we push the limits of multi-model workflows, it is crucial to pause and critically assess their current performance and reliability. Given the substantial cost associated with these workflows, including heavy CPU/GPU compute, extensive data handling, and extended runtimes, identifying failures only at the final stages can lead to exponentially costly repercussions.
Defining Key Terminology
To understand this better, let's define some working terminology:
Node: An atomic unit within a workflow, such as a model call, a data formatting operation, or an aggregation step.
Workflow: An end-to-end sequence of nodes with defined entry and exit points.
Metrics: Hyperparameters influencing workflow performance:
Probability that a node successfully completes a task (defining success and failure itself is an intricate topic addressed later):
Maximum number of retries configured for each node:
Probability that the workflow ends in a successful state, given n nodes:
Probability and Workflow Reliability
Considering a base scenario, we calculate the probability of node failure after retries:
Failed to render LaTeX expression — no expression found
Hence, the probability of node success becomes:
Thus, the workflow's overall success probability is:
Observations from Probability Analysis
Analyzing relationships between metrics reveals critical insights (x axis denotes number of steps n):
Scenario 1 (Single Attempt, Moderate Probability):
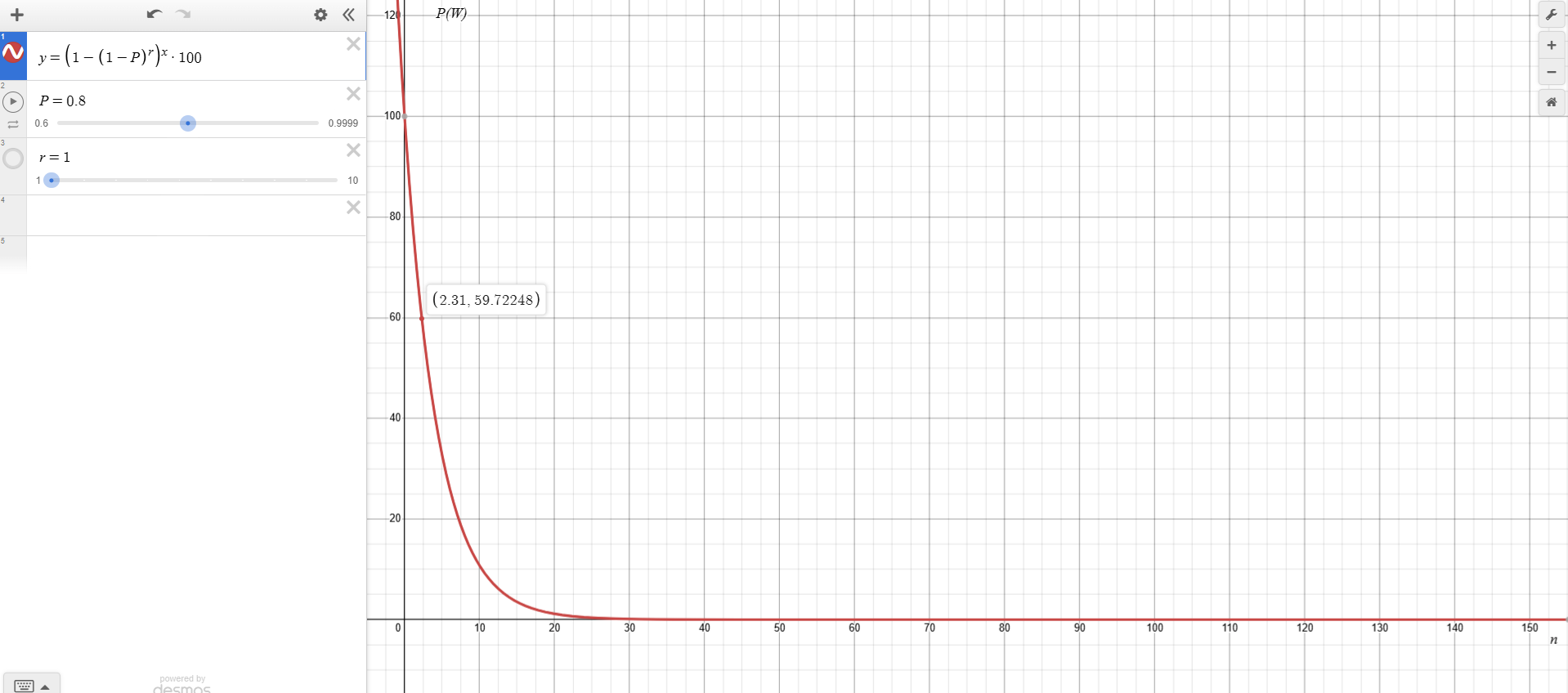
A workflow with even two sequential steps has less than a 50% chance of success if each step has an 80% success rate.
Scenario 2 (Single Attempt, High Probability):
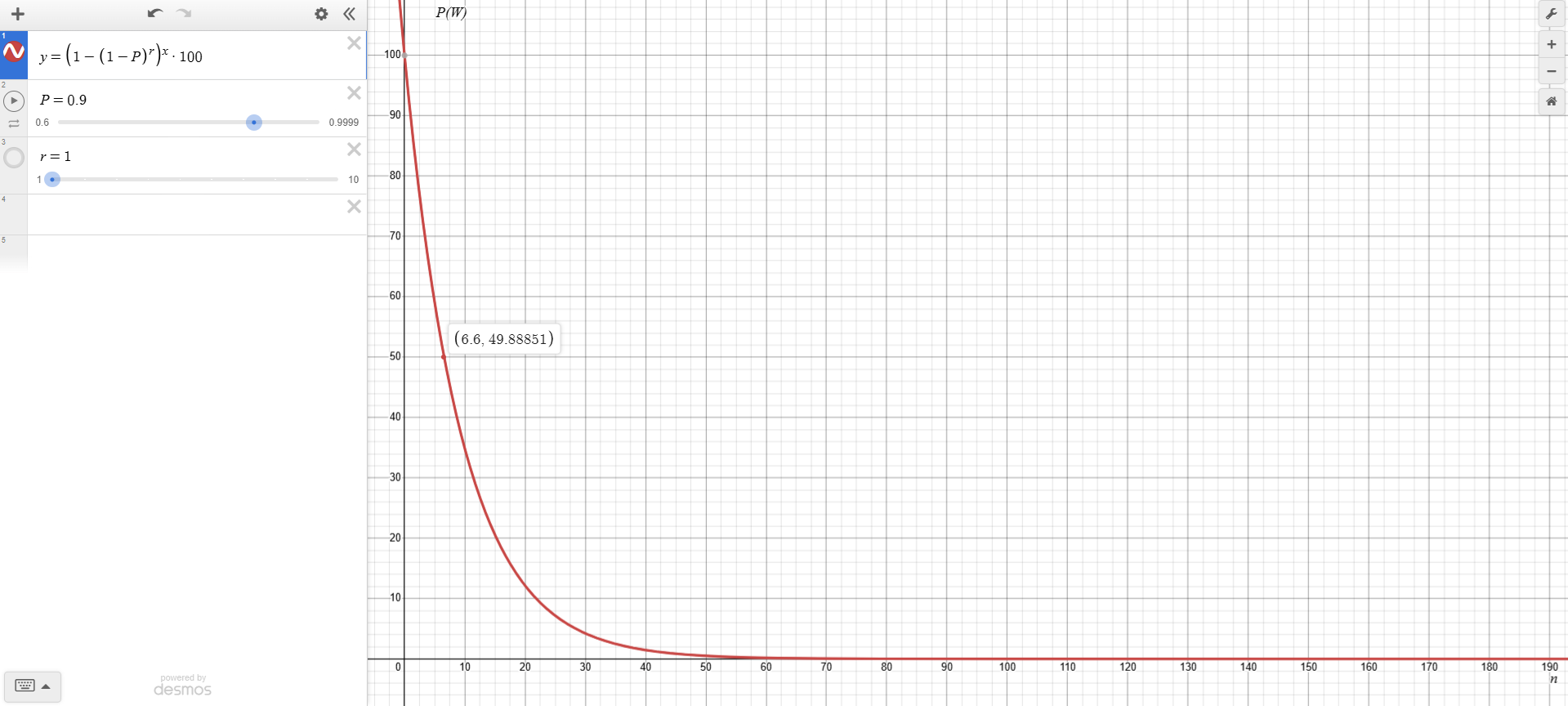
In this case 2-step workflow reaches around 80% reliability, but reliability drops significantly beyond six steps
Impact of Retries
What if we are able to accurately identify failures and trigger immediate retries, how do the numbers change?
Including retries dramatically improves reliability:
Moderate Probability (80%) with Retries:
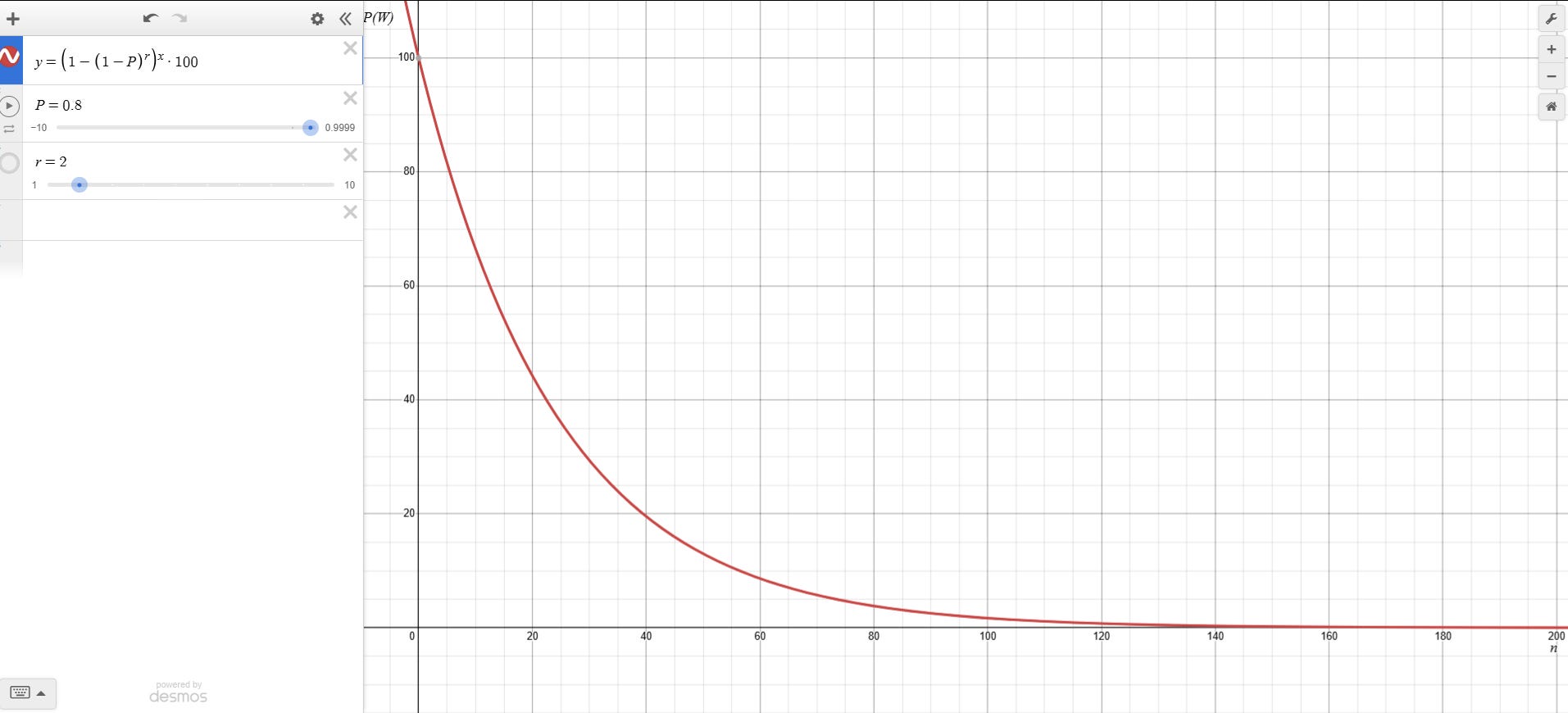
With just a single retry on failure, at accuracy as low as 80% we are able to run workflows with much larger sequences! Comparing to the 2-step workflow failing with no checks, this is a significant improvement.
And if we consider higher probablity of per node success, numbers shine even brighter:
Higher Probability (90%) with Retries:
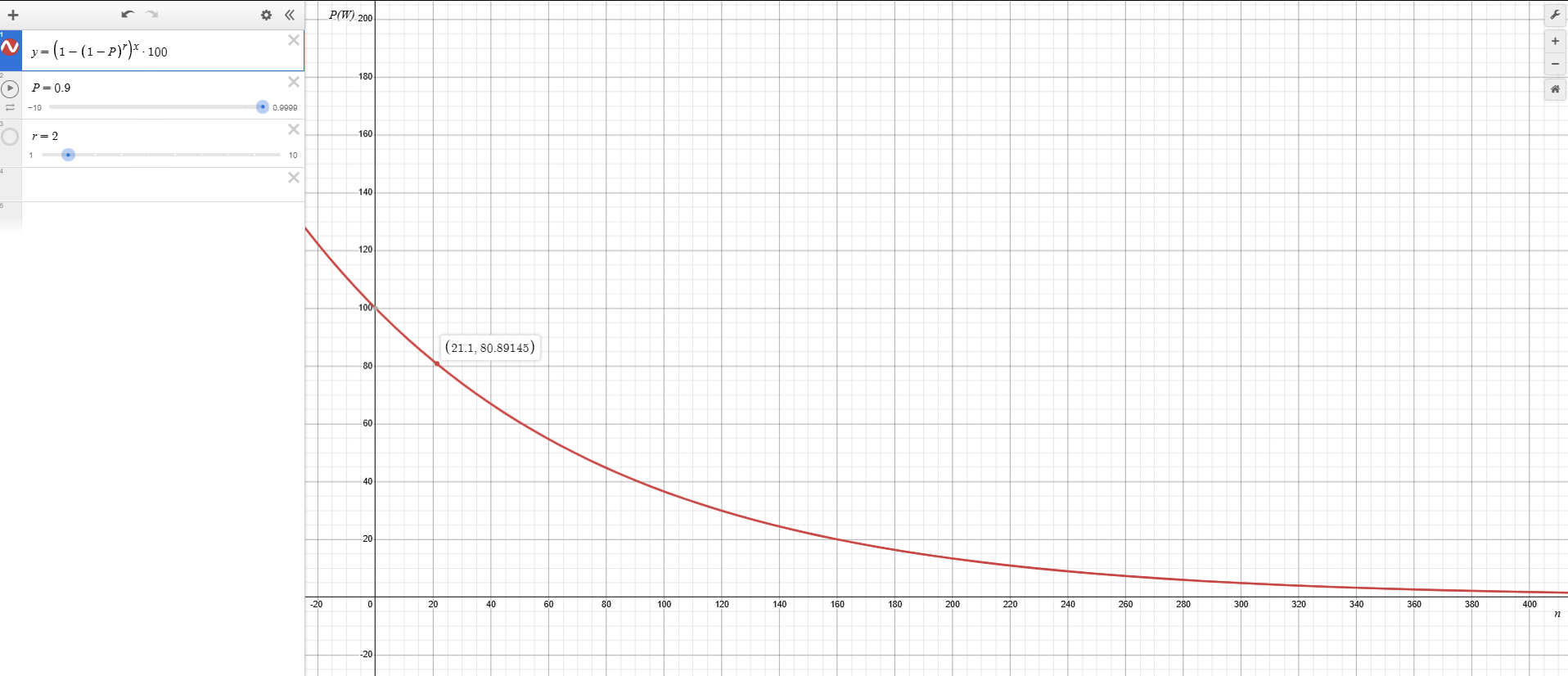
Only now do we start seeing longer (>20 step workflows) to have a chance at running reliably.
Furthermore, with higher intelligence and increased retries (e.g., r=4), even extensive workflows (e.g., 100-step workflows) achieve remarkably high reliability, approaching 99.9%.
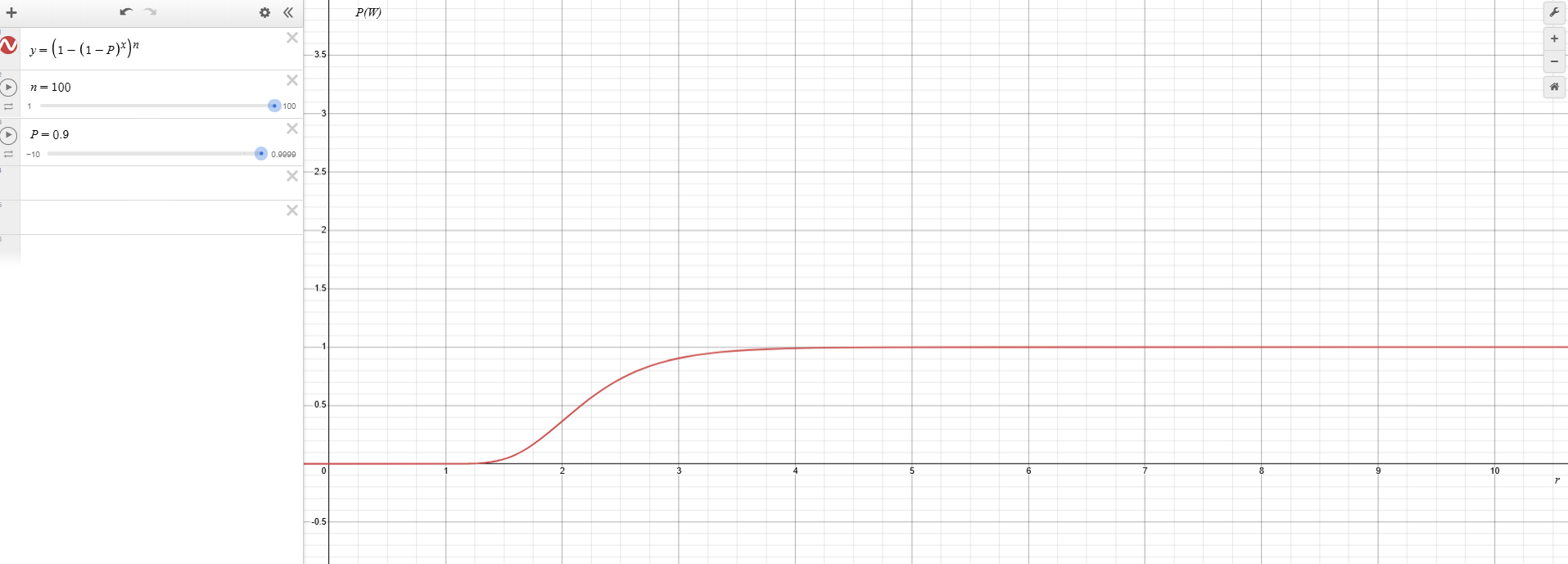
Plotting P(W) against number of retries at number of steps = 100. We see P(W) stabilises at r=4 considering P=0.9
What has been your experience working with AI agents with successive non-deterministic steps?
Why Node-level Failure Detection Matters
Effective AI workflows rely heavily on accurately detecting and addressing failures at each individual step or node. Implementing robust node-level checks rather than solely depending on end-to-end workflow validations provides substantial benefits:
Reduced Resource Wastage: Quickly identifying and resolving node failures prevents repeated, costly retries of the entire workflow.
Improved Reliability: Early detection enables granular retry logic, improving workflow resiliency and uptime.
Enhanced Debugging Capabilities: Pinpointing failures at the node level simplifies debugging, offering clearer visibility into which component failed and why.
In large-scale AI workflows, single-node failures if left unchecked can propagate silently and magnify resource usage exponentially, leading to cascading failures and degraded performance.
How to?
Identifying Failures in Non-deterministic Nodes
Non-deterministic nodes such as LLM-generated content, probabilistic algorithms, and stochastic processes introduce unique challenges in identifying failures accurately. Unlike deterministic tasks, outputs from these nodes vary naturally, complicating the differentiation between acceptable variance and genuine failures.
Several effective strategies to tackle these challenges include:
Hybrid Evaluation Techniques
Hybrid evaluation blends deterministic checks with statistical or heuristic indicators. This method improves robustness by assessing multiple indicators rather than relying on binary pass/fail outcomes. Techniques include:
Confidence Score Thresholding: Using model confidence metrics to evaluate if node outputs are within acceptable thresholds.
Statistical Heuristics: Establishing expected distributions or statistical bounds (e.g., KL-divergence, Jensen-Shannon divergence) to identify anomalies or outliers.
Drift Detection Algorithms: Implementing methods like Adaptive Windowing (ADWIN) or Kolmogorov–Smirnov tests to dynamically assess node performance against expected behavior.
LLM-based Judging Systems
Utilizing advanced language models as evaluative judges provides a powerful mechanism for validating outputs of non-deterministic nodes. In practice, this involves:
Prompt-based Validation: Generating structured prompts to solicit detailed evaluations of task outcomes from an LLM (e.g., GPT-4, GPT-4o).
Self-consistency Checks: Using multiple samples or chain-of-thought reasoning to improve the reliability of the evaluation.
Meta-evaluation Layers: Applying hierarchical evaluations, where one LLM judges node outputs and another assesses the reliability of the first evaluator, thus improving overall accuracy.
While highly effective, these methods may introduce additional latency and computational costs. Balancing these trade-offs requires careful calibration to workflow demands.
Intelligent Failure Handling
Beyond detection, intelligently handling failures is essential for robust workflows. Strategies include:
Dynamic Retry Logic: Implementing adaptive retry mechanisms, such as exponential backoff combined with smart checkpointing, to reduce resource usage without compromising reliability.
Task-Specific Error Handling: Developing tailored responses to node-specific failures, for example, fallback methods, alternative models, or parameter adjustments to minimize workflow interruptions.
Resource-aware Retries: Integrating resource estimation models (e.g., predictive cost and compute time) into retry decision-making, ensuring retries occur only when justified by resource efficiency and probability of success.
Choosing the Right Evaluation Method
Selecting suitable evaluation metrics or criteria involves detailed trade-off analysis:
Accuracy vs. Overhead: Choosing metrics that offer the best compromise between evaluation accuracy and computational or latency overhead. High-stakes nodes may justify resource-intensive evaluations, whereas lower-impact nodes require lightweight heuristics.
Node-specific Metrics: Employing specialized metrics aligned closely with node functionality. Examples include BLEU scores for language generation tasks, Structural Similarity Index (SSIM) for visual outputs, or F1 scores for classification tasks.
Operational Benchmarks: Integrating operational metrics such as memory usage, inference latency, or CPU/GPU utilization to proactively identify performance degradation that precedes outright failures.
Parallelization: Maximizing Reliability Without Latency
Parallelization significantly enhances workflow robustness by addressing multiple potential failure points simultaneously. Effective parallelization involves:
Concurrent Execution of Critical Nodes: Ensuring that critical or failure-prone tasks run in parallel with redundancy (replicated nodes), preventing single points of failure.
Preemptive Checks and Parallel Validation: Performing concurrent validation tasks to promptly isolate failures, allowing recovery measures before the primary workflow is disrupted.
Fine-Grained Node Splitting: Breaking down complex nodes into smaller, concurrent tasks that can be executed and validated independently, facilitating quicker failure detection and reducing rollback overhead.
Advanced orchestration tools (e.g., Apache Airflow, Kubernetes Jobs, Exosphere, AWS Step Functions) are often leveraged to efficiently manage parallel execution, providing built-in fault tolerance, automatic retry mechanisms, and granular monitoring.
Make your AI agent fail fast to succeed
As AI workflows scale in complexity and criticality, implementing sophisticated node-level failure detection, intelligent retry strategies, and well-orchestrated parallelization becomes imperative. These technical measures ensure robust, efficient operations, reduce computational waste, and mitigate costly downtime.
Embracing these best practices brings us closer to achieving truly autonomous, reliable, and resource-efficient AI systems, capable of handling increasingly complex, long-duration tasks at scale.
How are you measuring success and achieving it?