

More GPUs Won't Save You
The Memory Wall Crisis That's Reshaping AI Infrastructure

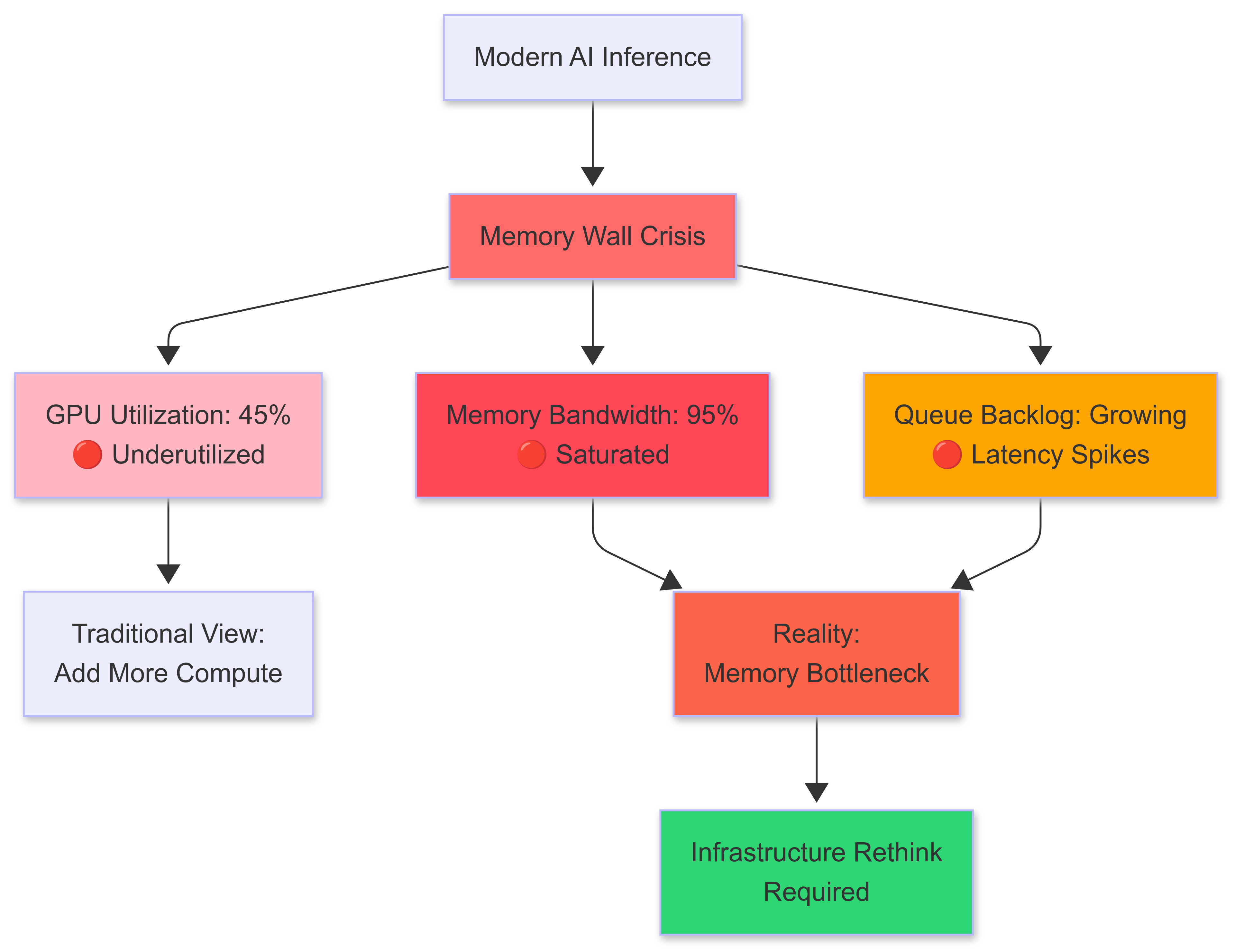
The bottleneck has shifted. While everyone's been obsessing over compute scaling more GPUs, bigger clusters, faster interconnects a quieter crisis has been building in the shadows. We're hitting the memory wall in AI inference, and it's fundamentally changing how we need to think about serving large language models at scale.
Having worked on inference infrastructure at scale, I've watched this transition happen in real-time. The symptoms are everywhere: GPU utilization dropping despite queues backing up, latency spikes that don't correlate with compute load, and throughput plateaus that no amount of additional hardware seems to break through.
The math is unforgiving, and it's time we talked about it.
The Fundamental Problem
Modern LLMs are memory-bound, not compute-bound. This isn't immediately obvious because training workloads which dominate the narrative are the opposite. Training saturates compute with dense matrix multiplications across massive batches. Inference, particularly for generation tasks, tells a different story entirely.
Consider the memory requirements for serving a 70B parameter model:
Model weights: 70B parameters × 16 bits = 140 GB (FP16)
KV cache per sequence: ~2 GB for 4K context (depending on model architecture)
Activation memory: Variable, but typically 1-4 GB during forward pass
For a single H100 with 80GB HBM, you're already at the limit with just the model weights. Add concurrent sequences with their KV caches, and you quickly understand why memory bandwidth not FLOPS determines your serving capacity.
Let's formalize this. For autoregressive generation, each token requires:
Where:
W = Model weights read (constant per token)
KVread = Key-value cache read (grows with sequence length)
KVwrite = Key-value cache write (new key-value pairs)
A = Activation memory (varies by layer)
The key insight: W dominates early in generation, but as sequences grow longer, KV the bottleneck. This creates a non-linear relationship between sequence length and memory pressure that most serving systems handle poorly.
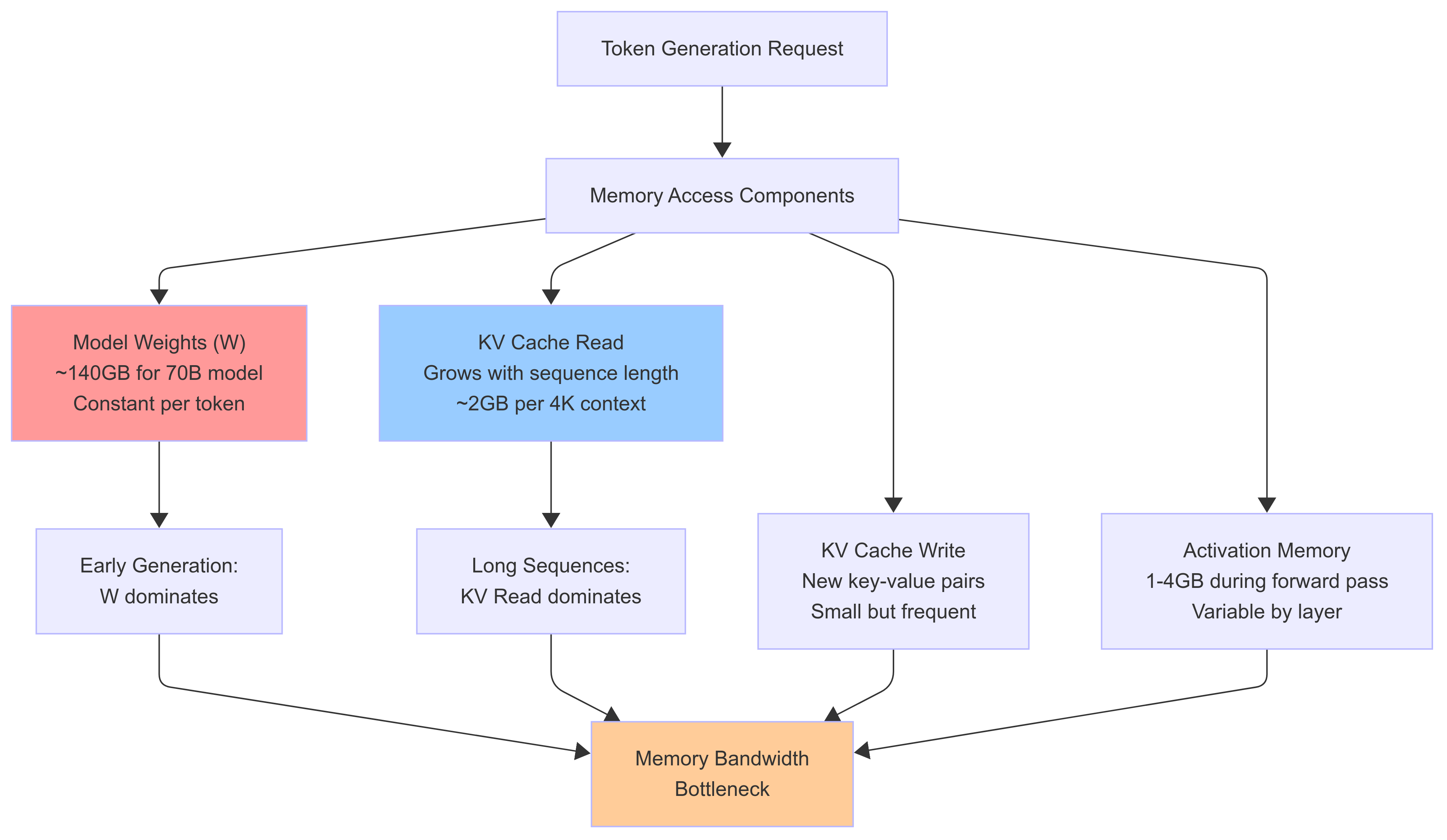
Memory access components during autoregressive generation. Note how KV cache reads dominate as sequence length increases.
The Arithmetic of Memory Bandwidth
Let's work through a concrete example. An H100 has roughly 3 TB/s of memory bandwidth. For a 70B parameter model at FP16:
Weight access per token: 140 GB
Theoretical max tokens/sec: 3,000 GB/s ÷ 140 GB = ~21 tokens/sec
This is the absolute ceiling for a single sequence, assuming perfect memory access patterns and zero overhead. In practice, you get maybe 60-70% of this due to:
Memory access inefficiencies
KV cache overhead growing with sequence length
Attention computation patterns
System overhead
So realistic peak throughput is closer to 12-15 tokens/sec for long sequences on a single H100. Now consider batching multiple sequences:
Where N is batch size and α represents the KV cache access pattern efficiency. As batch size increases, the weight reads are amortized across sequences, but KV cache pressure grows quadratically with both batch size and sequence length.
This creates an optimization surface that most serving frameworks haven't properly mapped. The sweet spot isn't just about maximizing batch size it's about finding the optimal balance between batch size, sequence length, and memory access patterns.
Why Current Solutions Fall Short
Most inference serving solutions treat memory as an afterthought. They focus on request routing, model loading, and compute scheduling, but ignore the fundamental memory access patterns that determine actual performance.
Static Batching assumes uniform sequence lengths and fails catastrophically when real traffic arrives with mixed lengths. A batch with one 8K sequence and seven 1K sequences performs worse than eight 1K sequences due to memory access patterns.
Naive KV Caching stores key-value pairs contiguously in memory, creating fragmentation and inefficient access patterns as sequences grow and shrink dynamically.
Compute-First Scheduling allocates GPUs based on model size and expected compute load, ignoring memory bandwidth utilization. You end up with GPUs sitting idle while memory controllers are saturated.
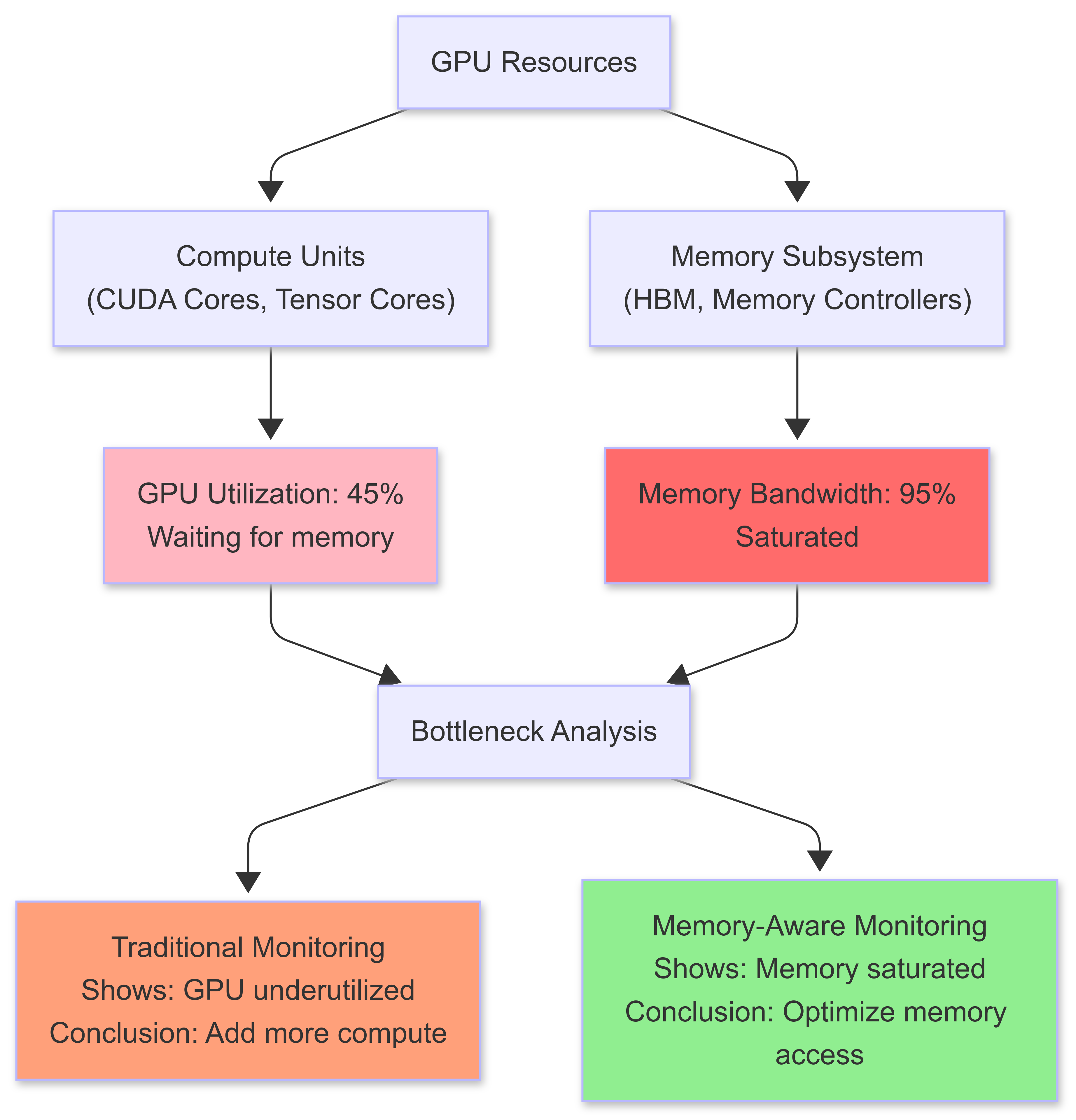
Typical production scenario: GPU compute utilization remains low while memory bandwidth saturates, creating a hidden bottleneck.
The result? Serving systems that look good on paper but collapse under real production loads.
Memory-Aware Serving Patterns
The path forward requires treating memory bandwidth as a first-class resource, just like compute. Here are the patterns that actually work at scale:
1. Dynamic Memory-Aware Batching
Instead of fixed batch sizes, implement dynamic batching that considers memory access patterns:
# Exosphere Node: Memory-Aware Dynamic Batching
class MemoryAwareBatchingNode(BaseNode):
class Inputs(BaseModel):
requests: str
memory_budget_gb: str
class Outputs(BaseModel):
optimized_batch: str
estimated_memory_usage: str
async def execute(self) -> Outputs:
# Sort requests by sequence length for memory locality
sorted_requests = sort_by_sequence_length(self.inputs.requests)
# Greedy batch composition within memory budget
batch = []
memory_used = 0.0
for request in sorted_requests:
memory_cost = estimate_memory_cost(request, len(batch))
if memory_used + memory_cost <= self.inputs.memory_budget_gb:
batch.append(request)
memory_used += memory_cost
else:
break # Budget exceeded
return self.Outputs(
optimized_batch=batch,
estimated_memory_usage=memory_used
)
The key insight: sequence length homogeneity within batches dramatically improves memory efficiency.
2. Streaming KV Cache Management
Rather than allocating fixed KV cache blocks, implement streaming cache management that adapts to actual usage patterns:
Chunked allocation: Allocate KV cache in fixed-size chunks rather than per-sequence
Memory pooling: Reuse deallocated chunks across sequences
Predictive prefetching: Prefetch likely-to-be-accessed cache lines based on attention patterns
3. Memory Bandwidth Scheduling
Schedule requests based on memory bandwidth utilization, not just compute availability:
# Exosphere Node: Memory Bandwidth Scheduler
class MemoryBandwidthSchedulerNode(BaseNode):
class Inputs(BaseModel):
request: InferenceRequest
peak_bandwidth_gb_per_sec: str
current_utilization: str
class Outputs(BaseModel):
can_schedule: bool
estimated_bandwidth_usage: str
utilization_after_scheduling: str
async def execute(self) -> Outputs:
# Calculate bandwidth requirements for this request
bandwidth_needed = calculate_bandwidth_requirements(
model_weights=MODEL_SIZE_GB,
kv_cache_size=self.inputs.request.sequence_length,
expected_tokens=self.inputs.request.expected_tokens
)
# Apply safety margin (80% max utilization)
max_allowed = self.inputs.peak_bandwidth_gb_per_sec * 0.8
# Check if we can schedule without exceeding bandwidth limits
can_schedule = (
self.inputs.current_utilization + bandwidth_needed <= max_allowed
)
new_utilization = (
self.inputs.current_utilization + bandwidth_needed
if can_schedule else self.inputs.current_utilization
)
return self.Outputs(
can_schedule=can_schedule,
estimated_bandwidth_usage=bandwidth_needed,
utilization_after_scheduling=new_utilization
)
4. Speculative Memory Allocation
For multi-turn conversations and long-form generation, implement speculative memory allocation that reserves bandwidth for likely future requests:
# Exosphere Node: Speculative Memory Allocation
class SpeculativeMemoryNode(BaseNode):
class Inputs(BaseModel):
conversation_history: str
current_request: str
available_memory_gb: str
class Outputs(BaseModel):
memory_reservation: str
continuation_probability: str
predicted_output_length: str
async def execute(self) -> Outputs:
# Predict likelihood of conversation continuation
continuation_prob = estimate_continuation_probability(
self.inputs.conversation_history
)
# Predict output length based on prompt characteristics
predicted_length = predict_output_length(
self.inputs.current_request.prompt
)
# Calculate memory reservation strategy
base_memory = calculate_base_memory_requirement(
self.inputs.current_request
)
speculative_memory = (
continuation_prob *
predicted_length *
MEMORY_PER_TOKEN_GB
)
# Cap speculative allocation at 30% of available memory
total_reservation = min(
base_memory + speculative_memory,
self.inputs.available_memory_gb * 0.3
)
return self.Outputs(
memory_reservation=total_reservation,
continuation_probability=continuation_prob,
predicted_output_length=predicted_length
)
Orchestrating Memory-Aware Nodes
These individual nodes can be composed into a complete memory-aware inference pipeline using Exosphere's runtime:
# Exosphere Runtime: Memory-Aware Inference Pipeline
Runtime(
namespace="MemoryAwareInference",
name="memory-optimization-pipeline",
nodes=[
MemoryAwareBatchingNode, # Dynamic batching optimization
MemoryBandwidthSchedulerNode, # Bandwidth-aware scheduling
SpeculativeMemoryNode # Predictive memory allocation
]
).start()
# Alternative: Separate runtimes for different concerns
Runtime(
namespace="MemoryAwareInference",
name="batch-optimizer",
nodes=[MemoryAwareBatchingNode]
).start()
Runtime(
namespace="MemoryAwareInference",
name="bandwidth-scheduler",
nodes=[MemoryBandwidthSchedulerNode]
).start()
This modular approach allows you to scale different components independently based on your specific bottlenecks.
The Infrastructure Implications
Memory-aware serving changes infrastructure requirements fundamentally:
Hardware Selection: Memory bandwidth becomes the primary metric, not FLOPS. A GPU with 2x memory bandwidth but 0.8x compute is often better for inference workloads.
Cluster Architecture: Network topology matters less; memory hierarchy matters more. NUMA-aware scheduling and memory-local processing become critical.
Monitoring and Observability: Traditional metrics like GPU utilization become misleading. Memory bandwidth utilization, cache hit rates, and access pattern efficiency become the key indicators.
Cost Optimization: The cost model shifts from compute-hours to memory-bandwidth-hours. Suddenly, techniques like model quantization and sparse attention aren't just about model size they're about memory access efficiency.
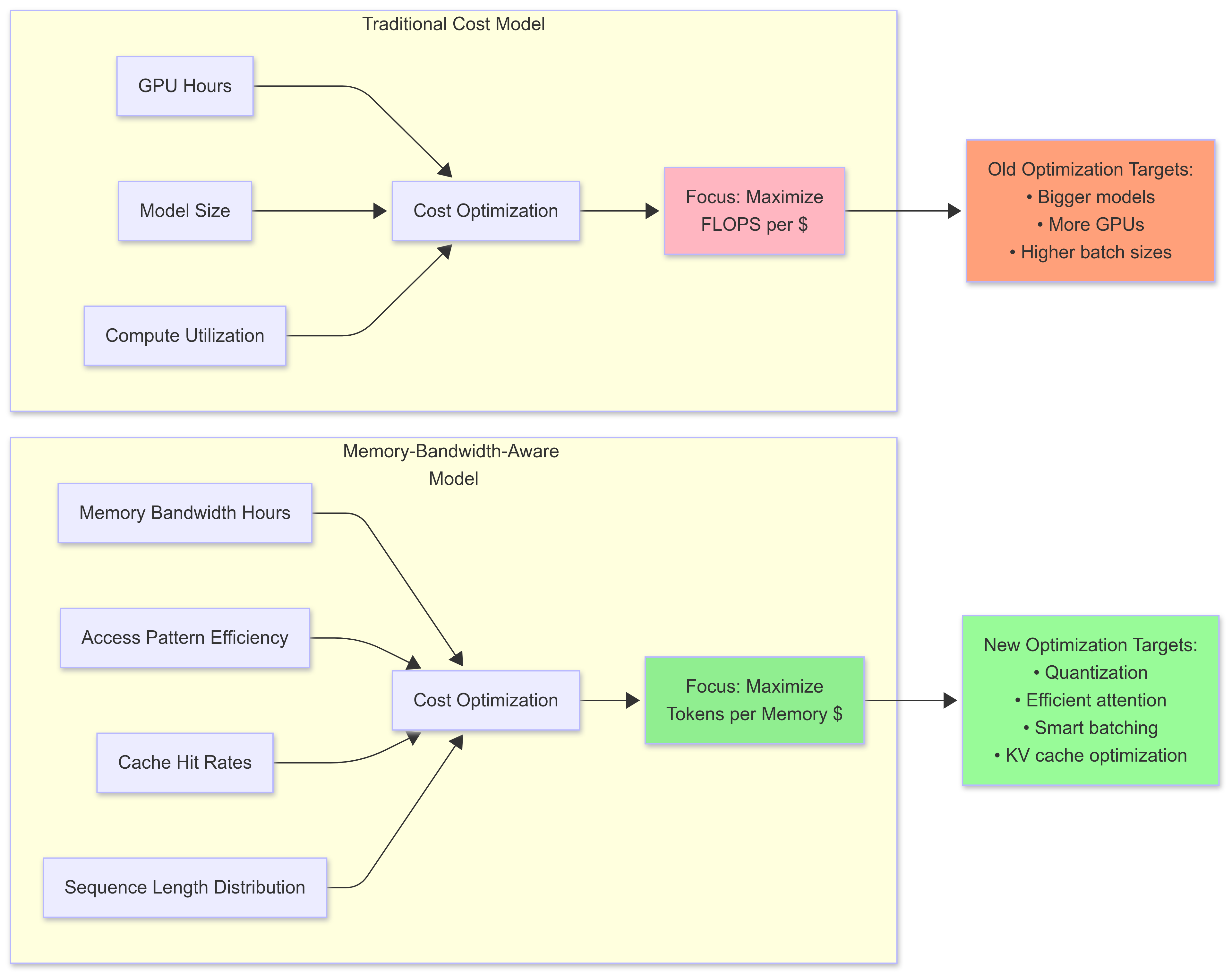
Traditional compute-centric cost model vs memory-bandwidth-aware cost model. The optimization targets shift dramatically.
What This Means for the Next Wave
The memory wall in AI inference is forcing a fundamental rethink of serving infrastructure. Just as the transition from CPU to GPU changed everything about training, the transition from compute-bound to memory-bound inference is reshaping the serving landscape.
Model Architecture Evolution: Future models will be designed with memory access patterns in mind, not just parameter count. Techniques like mixture-of-experts and dynamic routing become essential for memory efficiency.
Serving Framework Consolidation: Frameworks that understand memory bandwidth as a first-class resource will dominate. Those that don't will be relegated to toy demos and benchmarks.
Hardware-Software Co-design: The next generation of inference accelerators will be designed around memory bandwidth, with novel memory hierarchies and access patterns optimized for transformer workloads.
The Questions We Need to Answer
As we navigate this transition, several critical questions emerge:
How do we build serving systems that gracefully degrade under memory pressure rather than failing catastrophically?
What's the right abstraction for memory bandwidth scheduling across heterogeneous hardware?
How do we balance the tension between batch efficiency and tail latency when memory access patterns are non-uniform?
Can we develop memory access pattern prediction that's accurate enough to drive real-time scheduling decisions?
The memory wall isn't just a technical challenge it's an opportunity to build fundamentally better inference infrastructure. The teams that solve this first will have a massive advantage in the next phase of AI deployment.
What patterns have you seen in your inference workloads? Are you hitting memory bandwidth limits, or are there other bottlenecks I'm missing? The infrastructure that emerges from this transition will shape how we deploy AI for the next decade.
Thanks for reading,
Nikita Ag, AI Infra Weekly